
Image by: ismagilov, ©2017 Getty Images
As the demands for document processing become increasingly sophisticated and new automation technologies are made available, industry leaders are faced with a startling array of management challenges. When it comes to automated document capture, the range of investment required, in both time and money, varies significantly. Some companies only need to make documents easy to find, while others want to support a high-throughput for capturing transactional data, such as invoices or other complex documents.
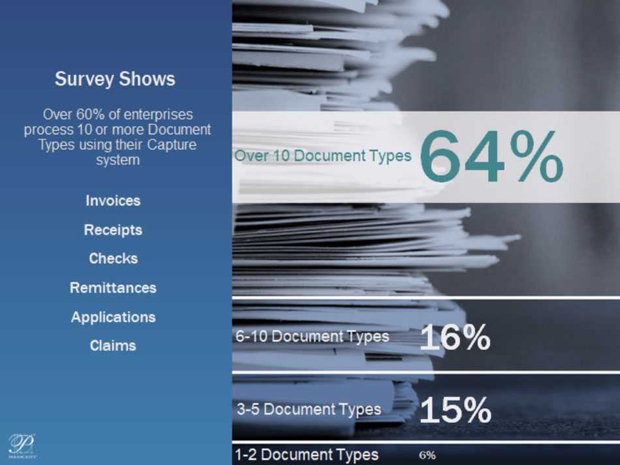
One aspect that drives complexity is the range of document types involved in targeted processes. A recent survey of enterprise capture operations, conducted by AIIM, revealed that over 60% of respondents are currently capturing more than 10 different document types. This data indicates that automated document processing continues to be leveraged, more than likely extending beyond a single business process, which is a positive trend toward increased efficiency.
Dealing with multiple document types creates complexity, which, if not proactively managed, increases costs. Multiple documents often require:
1. Managing different classification and extraction rules based upon document type.
If your process involves multiple documents, such as within mortgage processing, you are likely managing 10 different standard document types with significant variability among them. Not only do you have to properly identify them, but you have to do so when the documents may not look anything alike. You also have to identify document boundaries in instances where a large loan file is captured as a single file. For extraction, you’ll have to account for both standardized field locations on common documents, such as the HUD loan application, as well as highly variable documents, like those commonly used to verify proof of address.
Advanced capture systems, which provide flexible ways to classify documents beyond rule-based approaches, make the process of managing multiple document types much easier and, oftentimes, more reliable. For extraction, a system that provides multiple ways to locate needed data offers more flexibility and options to handle wide variances in documents.
2. Managing different configurations based upon source of document.
This area still has room for improvement, but progressive-thinking solution providers are expanding support of native electronic documents that combine the benefits of electronic documents (think “no need to apply optical character recognition”) with the advantages of page-level image analysis. The result is a single system that can deliver a higher level of both accuracy and throughput without having to create specialized configurations.
4. Effort for specialized tuning and upkeep.
Advanced capture systems, which provide flexible ways to classify documents beyond rule-based approaches, make the process of managing multiple document types much easier and, oftentimes, more reliable. For extraction, a system that provides multiple ways to locate needed data offers more flexibility and options to handle wide variances in documents.
2. Managing different configurations based upon source of document.
Most staff charged with managing a capture system have disdain for documents that come through fax. This is because the image quality and characteristics can vary significantly, making faxes difficult to process. It’s always best when the organization can control how documents are captured. However, the trend of pushing document capture to the periphery of a process places strain on the ability to manage multi-channel capture, including mobile. Often, a system must be configured for each input source.
Increasingly, the staid document preprocessing technologies have evolved beyond the basic commoditized noise, orientation, and contrast control to now include advanced image processing, with automated resolution detection and correction, adaptive conversion of images with different quality, and automated correction of image distortion common with documents captured via mobile and fax.
3. Managing different workflows based upon different file types.
Increasingly, the staid document preprocessing technologies have evolved beyond the basic commoditized noise, orientation, and contrast control to now include advanced image processing, with automated resolution detection and correction, adaptive conversion of images with different quality, and automated correction of image distortion common with documents captured via mobile and fax.
3. Managing different workflows based upon different file types.
Just as input channel trends are having an impact on document processing, so is the expansion of various file types. Long gone are the days where everything was scanned as a TIFF. Now, we must not only consider multiple image types but also the increasing need to capture electronic documents of every kind as companies continue to progress through digital transformation. In many instances, document processing cannot deal with multiple document types at all or must accommodate this need either through various software components, different configurations, or by transforming digital documents into images.
This area still has room for improvement, but progressive-thinking solution providers are expanding support of native electronic documents that combine the benefits of electronic documents (think “no need to apply optical character recognition”) with the advantages of page-level image analysis. The result is a single system that can deliver a higher level of both accuracy and throughput without having to create specialized configurations.
4. Effort for specialized tuning and upkeep.
This issue is probably the least understood, let alone managed. The real value of automated document processing is to put as much of it into a “straight through” process, where no human interaction is needed. To get there, it requires a lot of analysis, configuration, measurement, and tuning for each document variation (type, input source, file type, etc.). The more documents, the more investment required. The reality is that most automated document processing is closer to a supervised process versus something truly automated—with the outcomes of the major steps, such as classification, document separation, and data extraction, all being 100% reviewed to ensure accuracy. This is akin to a person reviewing and approving every action of an autonomous driving vehicle instead of being able to read a book or play Candy Crush while driving. The actual value of automated document processing in most organizations has yet to be achieved.
Despite accuracy claims from most vendors, the reality is that most of the performance measurement capabilities focus on measurement of optical character recognition (OCR) accuracy through data correction activities that provide a more static view of the achieved accuracy. While this knowledge is interesting, it doesn’t provide insight into how to improve the system. Some advanced capture systems can provide automation for adjusting rules based upon user feedback. This is definitely moving the industry in the right direction, and yet, we are still far from the day when a system can be deployed and can autonomously improve through observation of daily production activities without any human intervention.
Despite accuracy claims from most vendors, the reality is that most of the performance measurement capabilities focus on measurement of optical character recognition (OCR) accuracy through data correction activities that provide a more static view of the achieved accuracy. While this knowledge is interesting, it doesn’t provide insight into how to improve the system. Some advanced capture systems can provide automation for adjusting rules based upon user feedback. This is definitely moving the industry in the right direction, and yet, we are still far from the day when a system can be deployed and can autonomously improve through observation of daily production activities without any human intervention.
Greg Council is Vice President of Marketing and Product Management at Parascript, responsible for market vision and product strategy. He oversees all aspects of Parascript Artificial Intelligence software life cycles, leading the successful development and introduction of advanced machine learning technology to the marketplace. Contact him by visiting www.parascript.com or follow Parascript on Twitter @ParascriptLLC.






